









ローカルでの画像生成 AI といえば、ComfyUI や Stable Diffusion WebUI などを使うイメージが強いかもしれません。
僕自身も画像生成をするときは ComfyUI を使うことが多いのですが、「Ollama だけで画像生成もできるのかな?」と気になり、実際に試してみました。
最近では Ollama でも画像生成に対応したモデルが公開されており、CLI から手軽に画像を生成できるようになっています。
この記事では、Ollama で利用できる画像生成モデル z-image-turbo と flux2-klein を実際に試しながら、使い方や生成結果、試して分かったことをまとめます。
「Ollama で画像生成できるの?」「どんなモデルが使えるの?」という方は、ぜひ参考にしてください。
Ollama で画像生成はできる?
結論からいうと、Ollamaでも画像生成はできます。
ただし、すべてのモデルが画像生成に対応しているわけではなく、画像生成専用のモデルを利用する必要があります。
また、記事執筆時点では、Ollama の画像生成機能は macOS のみで利用できます。Windows や Linux にはまだ対応していません。
現在、Ollama で動かせる画像生成モデルとして広く知られている(あるいは実験的に利用できる)主なものには、次の2つが挙げられます。
- z-image-turbo
- flux2-klein
※今後さらにモデルが追加される可能性がありますが、今回はこの2つのモデルをピックアップします。
どちらもプロンプトを入力するだけで画像を生成でき、生成した画像は PNG 形式で保存されます。
次の章では、それぞれのモデルの特徴を簡単に紹介します。
Ollama で使える画像生成モデル
記事執筆時点で、Ollama で手軽に試せる代表的な画像生成モデルを2つご紹介します。
| モデル | 特徴 |
|---|---|
| z-image-turbo 約13GB | リアルな写真風の画像生成が得意 |
| flux2-klein 約5.7GB(4B) | 軽量で高速。文字入り画像やデザイン系にも強い |
それぞれ特徴が異なるため、用途に応じて使い分けることができます。
z-image-turbo
z-image-turbo は、Alibaba の Tongyi Lab が公開している画像生成モデルです。
写真のようなリアルな画像を得意としており、人物や風景、商品画像などを自然な品質で生成できます。
また、英語や中国語の文字を比較的きれいに描画できることも特徴です。
なお、記事執筆時点では z-image-turbo は Apache License 2.0 で公開されています。
比較的自由に利用しやすいライセンスですが、実際に商用利用する際は最新のライセンス内容も確認しておくと安心です。
ollama run x/z-image-turboflux2-klein
flux2-klein は、Black Forest Labs が公開している画像生成モデルです。
4B と 9B の2つのサイズが用意されており、軽量ながら高品質な画像を生成できます。
特に、画像内の文字表現や UI デザイン、商品イメージの生成に強く、テキスト入りの画像を作りたい場合にも適しています。
なお、flux2-klein はモデルサイズによってライセンスが異なります。
今回試した 4B モデルは Apache License 2.0 ですが、9B モデルは Black Forest Labs 独自ライセンスとなっており、利用条件が異なります。
利用前には対象モデルのライセンスを確認することをおすすめします。
ollama run x/flux2-klein今回は、この2つのモデルを実際に試しながら、画質や生成傾向、プロンプトへの反応の違いを見ていきます。
実際に試してみた
ここからは、実際に Ollama で画像を生成しながら、それぞれのモデルを試していきます。
検証では、できるだけ条件を揃えるため、同じ内容のプロンプトを各モデルに入力して比較しました。
検証(1)同じプロンプトで画質を比較
まずは、同じプロンプトで画像を生成し、仕上がりの違いを比較します。
A red vintage car parked on a rainy street at night, cinematic lighting, photorealistic
z-image-turbo の生成結果

車体のディテールや金属部分の質感が自然で、写真のようなリアルな画像が生成されました。
プロンプトには「雨の街」と指定しましたが、雨粒はほとんど描かれず、雨上がりのような雰囲気に仕上がっています。
濡れた路面や背景のボケ表現も自然で、全体的に落ち着いた印象を受けました。
flux2-klein の生成結果

こちらも十分リアルな画像を生成できました。
z-image-turbo と比べると、雨粒や路面への映り込みがより強調されており、「雨の夜」というプロンプトを忠実に表現している印象です。
ライティングもドラマチックで、映画のワンシーンのような雰囲気に仕上がりました。
どちらも良い感じの写真が生成できました。ただ気になった点はナンバープレートの文字部分。文字が入りそうな部分は丁寧に指示したほうが良さそう。
検証(2)日本語プロンプトでも生成できるか
続いて、日本語でプロンプトを入力した場合の生成結果を確認します。
富士山を背景に、満開の桜並木を歩く黒猫。春の朝、写真のようにリアル。
z-image-turbo

日本語のプロンプトでも問題なく画像を生成できました。
富士山、満開の桜並木、黒猫といった要素がしっかり反映されており、日本語の理解力は十分高い印象です。
また、富士山にピントが合っているような構図になっており、背景まで含めた風景写真のような仕上がりになりました。
桜の花びらも細かく描写されていて、全体的にリアルな印象を受けます。
flux2-klein

こちらも日本語プロンプトを正しく解釈し、富士山、桜並木、黒猫を描画できました。
z-image-turbo とは異なり、黒猫にピントが合っているような描写になっており、主役が黒猫であることを強調した構図に感じます。
桜や富士山も十分きれいに描かれていますが、全体としては猫に視線が集まる写真のような仕上がりでした。
z-image-turbo の出力を最初見た時「黒猫ちゃんがボケてる」と違和感を感じました。ですが、よく見るとその周辺もボケていますので、ピントは自然に表現されているようにも思いました。意図した出力を得るには、どの部分にピントを合わせるかも指示したほうが良さそう。
検証(3)文字入り画像を生成してみる
続いて、画像内に文字を含むプロンプトを入力して試してみます。
モデル説明ページでも文字描画が特徴として紹介されているため、実際にどの程度再現できるのか確認しました。
最初は読み仮名を含めた以下のプロンプトを使用しました。
A clean white sign with the text “源勝(みなもとまさる)AI 実験室”
しかし、日本語部分はどちらのモデルでも崩れてしまい、正しく生成できませんでした。
そこで、読み仮名を除いた以下のプロンプトでも試しました。
A clean white sign with the text “源勝 AI 実験室”
こちらも結果はほぼ同じで、日本語の文字列は正しく描画されませんでした。
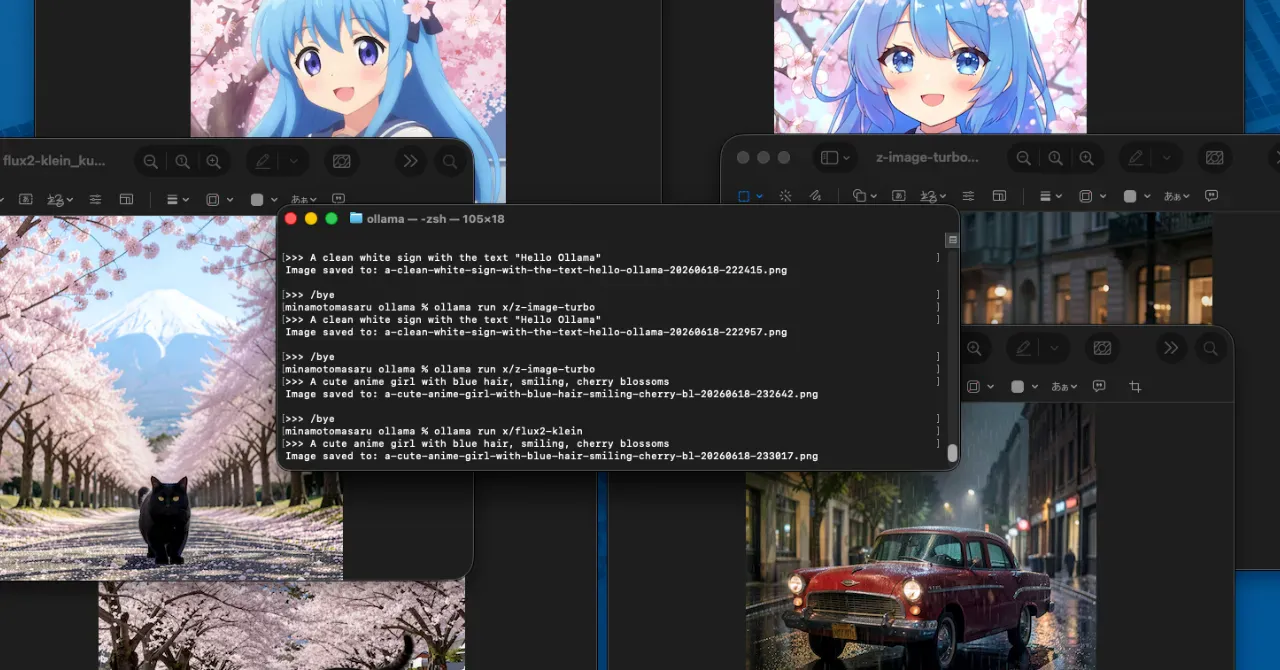
その後、英語のみのプロンプトでも試したところ、
A clean white sign with the text “Hello Ollama”
では、どちらのモデルも英字は比較的自然に描画できました。
z-image-turbo



日本語は文字として認識できないレベルまで崩れてしまい、実用的な結果にはなりませんでした。
一方で、英語の「Hello Ollama」は大きく崩れることなく描画されました。
ただし、「Hello Ollima」のように一文字違いになるケースもあり、英字は日本語より精度が高いものの、完全に正確というわけではありませんでした。
flux2-klein



こちらも日本語は正しく生成できませんでした。
英語については「Hello Ollama」を生成できましたが、m の文字がわずかに潰れたりズレたりするなど、細部の文字品質にはまだ改善の余地がある印象でした。
文字描画は英字で何度か試すと綺麗に出るかも?この結果を見るに、僕ならイラストや写真風の画像生成に専念させるかな。
検証(4)イラスト風画像を生成する
最後に、イラスト風のプロンプトを入力し、各モデルの表現の違いを比較してみます。
A cute anime girl with blue hair, smiling, cherry blossoms
z-image-turbo

「青い髪」「笑顔」「桜」という要素がしっかりと反映された、可愛らしいアニメ風の女の子が生成されました。
全体的に淡いライティングで、ふんわりとした柔らかいタッチで描かれているのが特徴的です。
どこか少し懐かしいような、セル画アニメのワンシーンを切り取ったような落ち着いた雰囲気に仕上がっています。
好みが分かれる部分かもしれませんが、こうした優しい風合いのイラストを出力したい場合には相性が良さそうです。
flux2-klein

こちらもプロンプトの要素を満たした、クオリティの高いイラストが生成されました。
z-image-turbo の柔らかい印象とは対照的に、flux2-klein は色使いが鮮やかで、瞳の描き込みなども細かく、現代のパキッとしたデジタルイラストのような仕上がりです。
ただ、よく観察してみると、女の子の髪の毛や顔よりも手前にあるはずの桜(花びらや枝)がうっすらと半透明になって透けており、レイヤーの重なりに少し違和感のある(AI 生成イラスト特有の少し破綻したような)箇所も見受けられました。
どちらのモデルもアニメ絵ができました!写真風だけでなく、アニメイラストも生成できるのは良い!
試して分かったこと
実際に2つの画像生成モデルを試してみると、使い勝手や得意なこと、少し気になった点も見えてきました。
思ったより簡単に画像生成できた
普段は ComfyUI などを使うことが多いのですが、それと比べると Ollama はとにかく手軽です。
モデルを起動して ollama run を実行するだけで、そのまま画像生成まで進められるので、WebUI を立ち上げたりブラウザを開いたりする必要がありません。
生成には数分かかりますが、「このプロンプトをちょっと試してみよう」と思ったときに、すぐ実行できる気軽さは想像以上でした。
画像の保存方法について
CLI から実行すると、生成された画像はカレントディレクトリへ PNG 形式で自動保存されます。
ファイル名もプロンプトやタイムスタンプをもとに自動で付けられるため、保存操作を意識しなくても画像が残っていくのは便利でした。
ただ、何枚も生成しているとフォルダ内がすぐ画像でいっぱいになるので、画像生成専用のディレクトリを作っておくと管理しやすいと思います。
日本語・英語プロンプトの使い勝手
風景や人物、猫や桜といった被写体の指定は、日本語でも十分に意図を理解してくれました。
英語へ翻訳する手間がないのは、普段使いではかなり便利です。
一方で、画像内に文字を描画させる用途では、日本語はまだ厳しい印象でした。今回試した範囲では、英語(英数字)の方が安定して文字を生成できました。
モデルごとの印象
🧠 z-image-turbo
リアルな写真風の表現が得意なモデルですが、イラストを描かせてもセル画のような柔らかい雰囲気に仕上がるのが印象的でした。
英字の描画精度も比較的高く、どんなプロンプトでも安定した結果を返してくれる、扱いやすいモデルだと感じます。
🧠 flux2-klein
色使いが鮮やかで、ライティングも印象的です。
一方で、イラストではレイヤーの重なりが少し不自然になるなど、AI らしいクセが見られる場面もありました。
それでも、インパクトのあるイラストや雰囲気重視の画像を作りたいときには、こちらのモデルの方が面白い結果になりそうです。
気になった点
実際に使ってみて、いくつか気になった点もありました。
🤔 画像サイズなど細かな調整は苦手
ComfyUI のように解像度や Seed 値を細かく調整しながら理想の1枚を探していく使い方には、現状の CLI はあまり向いていません。
「まず生成してみる」というシンプルな使い方を想定したツールという印象です。
🤔 メモリの要求はそれなりに高い
特に z-image-turbo は約13GBとモデルサイズが大きく、それなりのメモリ容量が欲しいと感じました。
今回使用した Mac mini M4(32GB)では問題なく動作しましたが、生成中はファンもしっかり回っており、それなりの負荷が掛かっていることが分かりました。
🤔 Open WebUI などとの連携は今後に期待
現在はチャット用 API と画像生成 API が分かれているため、普段使っている Open WebUI などから気軽に呼び出せないのは少し惜しいところです。
今後このあたりが改善されれば、より使いやすくなりそうだと感じました。
よくある質問(FAQ)
- QWindows や Linux でも Ollama で画像生成できますか?
- A
記事執筆時点では、Ollama の画像生成機能は macOS 向けとして提供されています。
Windows 版 や Linux 版 については、今後対応状況が変わる可能性があるため、最新情報は公式ドキュメントをご確認ください。
- QGemma 3 や 4 でも画像生成できますか?
- A
いいえ。Gemma 3 や 4 は画像を生成するモデルではありません。
画像の理解(画像を入力して内容を説明するなど)には対応していますが、画像を新しく生成する機能はありません。
- QOpen WebUI でも画像生成できますか?
- A
僕が試した環境では、チャット画面から x/flux2-klein を選択すると “does not support chat” というエラーになり、画像は生成できませんでした。
これは x/flux2-klein がチャットモデルではなく画像生成モデルであるためと考えられます。
Open WebUI には画像生成機能も用意されていますが、Ollama の画像生成モデルとの連携方法については今後の対応状況を確認する必要があります。
※ x/z-image-turbo も同様でした。
利用前にライセンスも確認しておこう
今回試した z-image-turbo と flux2-klein は、どちらも高品質な画像を生成できました。
ただし、画像生成モデルは性能だけでなく、ライセンスもモデルごとに異なります。
特に flux2-klein はモデルサイズによってライセンスが異なるため、仕事や商用利用を考えている場合は事前に確認しておくことが大切です。
Ollama 自体の商用利用や、モデルごとのライセンスの違いについては、以下の記事で詳しくまとめています。

まとめ
実際に試してみた結果、Ollama だけでも十分実用的な画像生成が行えることが分かりました。
もちろん ComfyUI のように細かなパラメータ調整まではできませんが、「思いついたプロンプトをすぐ試したい」という用途には非常に相性が良いと感じます。
特に ローカルLLM を普段から Ollama で利用している方なら、同じ操作感で画像生成まで試せるのは大きな魅力です。
今後 Windows や Linux への対応や、対応モデルが増えてくれば、Ollama の活用の幅はさらに広がっていくでしょう。
まずは z-image-turbo や flux2-klein で、ローカル環境での画像生成を体験してみてはいかがでしょうか。

