
ローカルLLM を安定して動作させるためには、メモリ(ユニファイドメモリ)の空き容量を確保することが非常に重要です。僕が現在メインで使用している「gpt-oss:20b」というモデルは、単体で 約14GB のメモリを占有します。
32GB のメモリを搭載した Mac mini M4 環境においても、他のアプリケーションやシステムによる消費を抑えることが、より賢いモデルを動かすための鍵となります。本記事では、僕が行った具体的なメモリ最適化手順を記録します。
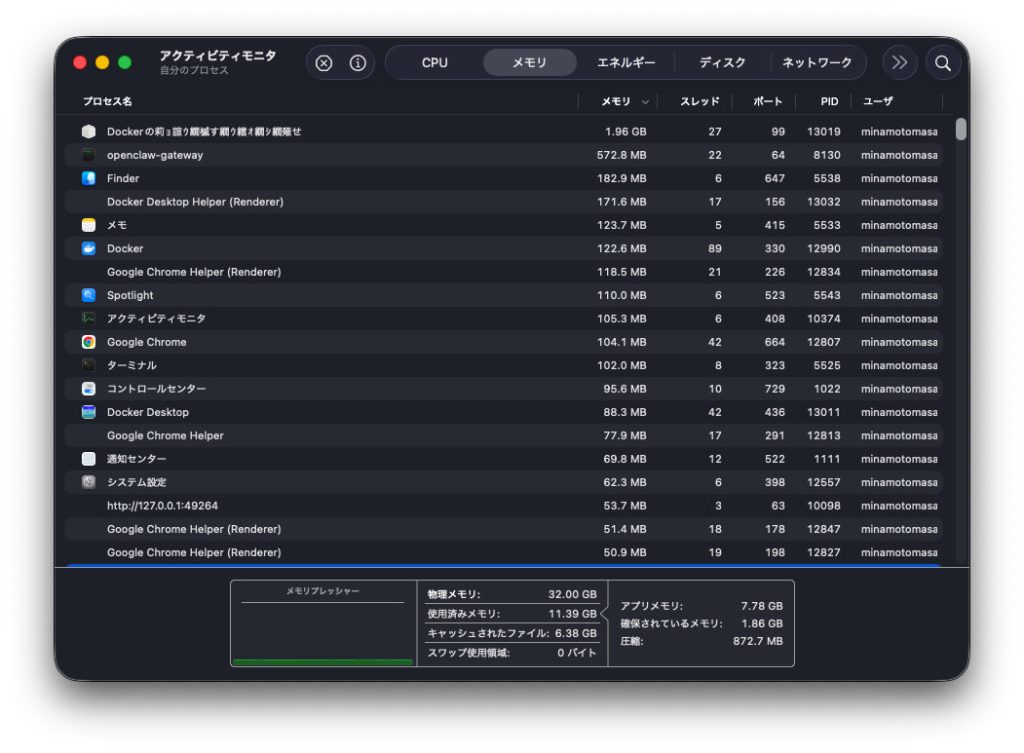
作業前のアクティビティモニタの確認
設定変更前のメモリ使用状況です。
不要なアプリケーションの停止
まずは、メモリ消費量の大きいアプリケーションを停止します。
Docker Desktop
コンテナを起動しているだけで 約2GB のメモリを消費していました。ローカルLLM の動作を優先するため、Docker 環境を一度停止する判断をしました。
Google Chrome
複数のタブを開くとメモリを大幅に消費するため、LLM実行時は最小限のタブに絞るか、ブラウザ自体を終了させます。
macOS システム環境設定の見直し
OSレベルで動作している、メモリやCPUリソースを消費する機能をオフにします。
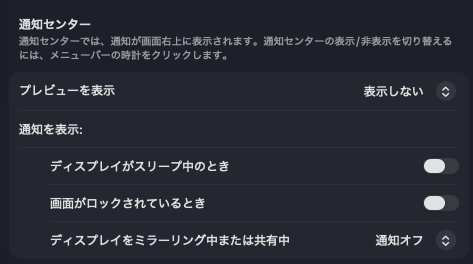
通知センター
バックグラウンドでの待機を減らすため、通知設定を最小限にします。
- プレビューを表示:表示しない
- 通知を表示
- ディスプレイがスリープ中の時:オフ
- 画面がロックされているとき:オフ
- ディスプレイをミラーリング中または共有中:オフ
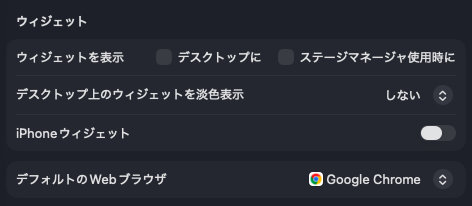
ウィジェット
デスクトップ上で常に動作するウィジェット機能を停止します。
- ウィジェット表示
- デスクトップに:オフ
- ステージマネージャー使用時に:オフ
- デスクトップ上のウィジェット淡色表示:しない
- iPhone ウィジェット: オフ
コントロールセンター
メニューバーの項目を整理し、バックグラウンド処理を削減します。
- 「コントロールを編集」ボタンより、不要な項目をすべて削除
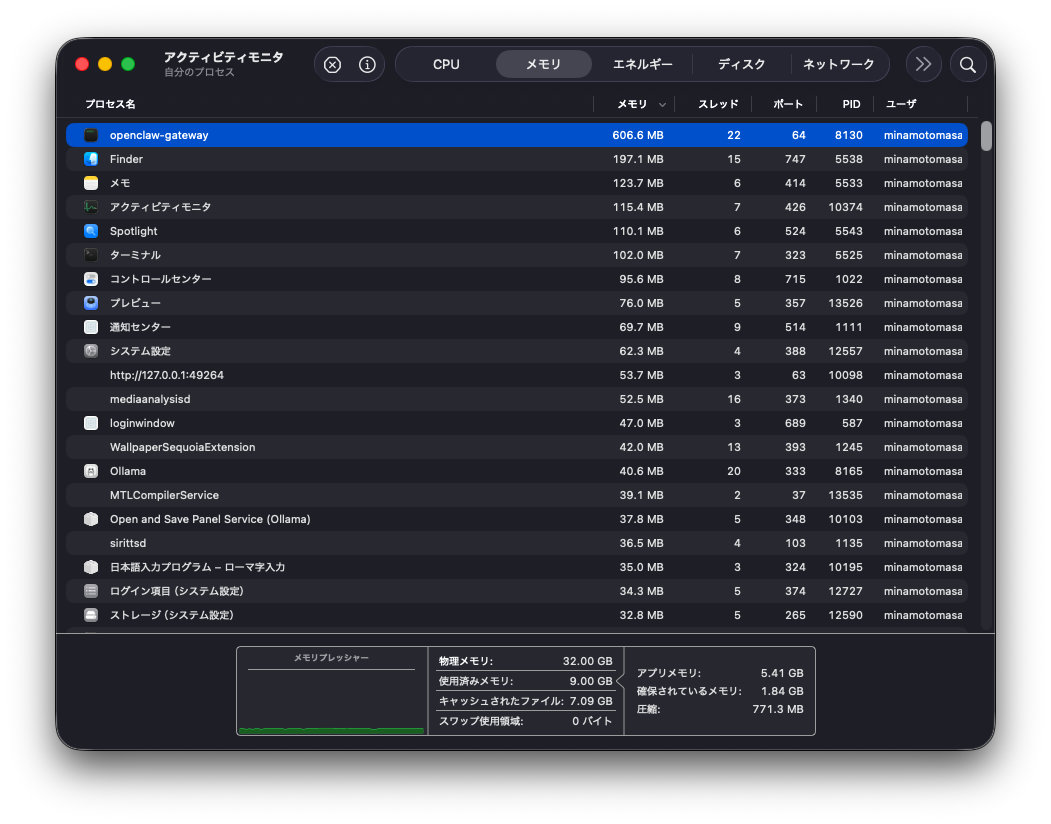
作業後のアクティビティモニタ
上記の設定を行った後のメモリ使用状況です。
まとめ
ローカルLLM の実行は、ハードウェアに非常に高い負荷をかけます。Mac mini M4 の 32GB というメモリ容量を最大限に活用するためには、こうした細かな設定の見直しが効果的であると考えています。
今後も、より負荷の高いモデルやエージェントを動かすためのチューニングを続けていきます。











